covid-19
index: [HOME] [Collecting data] [Deduplication] [Screening]
Screening and annotation of citations
When unique records are entered into the database, they are ready to be screening on eligibility and to be classified.
Annotation
We currently annotate, with the help of a ‘crowd’, the publications based on:
- Are they about SARS-CoV-2/COVID-19?
- What is the study design? annotation guide
- For epidemiological studies: in which country/countries are they conducted?
Purpose of the screening
- Allows other research groups to start with a curated dataset
- Serves as training set (machine learning, classification)
- Allows us to track the accumulation of evidence over time (similar to Counotte et al.)
- Preselection according to inclusion criteria
‘Crowd’ eligibility
People who are confidently able to differentiate between different study designs are welcomed to join the ‘crowd’. When potential contributors are unsure they are able to do the work, they can take a test: here.
Work distribution: using a ‘crowd’
To be able to distribute screening tasks to a ‘crowd’, we build a shiny app that communicates with the central database. Records are attibuted to members of the crowd for screening. When the task is completed, the decisions are verified by a second member of the crowd. Disagreement is resolved by the coordinator or by a third crowd member (Figure 1).
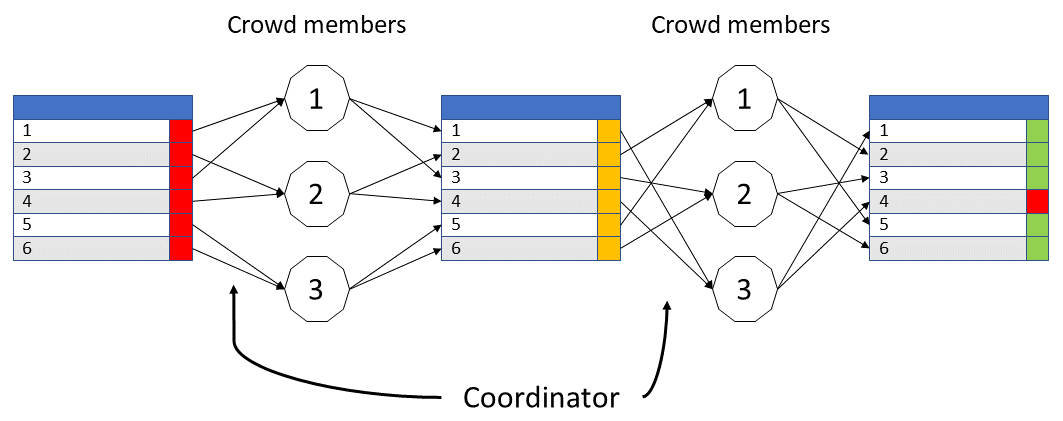 Figure 1. The workflow of screening and verification tasks. Crowd members are represented by numbered hexagons.
Figure 1. The workflow of screening and verification tasks. Crowd members are represented by numbered hexagons.
The screening app offers a login-protected environment that communicates with the central database. Crowd members are presented with citation information and are asked to make several decisions. Their decisions are submitted to the database.
Rapid screening using a R Shiny app
To accelerate the screening and verification of publications, we built a simple shiny app. This loads references and displays these to the reviewers. They execute their tasks in the shiny environment and decisions are logged into the central database. A demo of a simple screening app can be found here and the source code is available here.